我正在研究谷歌通用句子编码,我看到它使用简单的邻居/烦扰来为语义相似性搜索引擎找到最近的向量。这是我第一次听说。简单的邻居/烦恼是另一种寻找最近邻居的机器学习算法吗?它类似于 K 最近邻算法吗?
Annoy 是一种寻找最近邻居的机器学习算法吗?它类似于K最近邻算法吗?
数据挖掘
机器学习
nlp
算法
k-nn
2022-03-05 14:12:44
1个回答
没有足够的声誉来评论资源,所以我自己回答这个问题。
关于烦人
Annoy 是一个用于查找近似最近邻居的库,近似是这里的关键词。
了解 K-NN 和近似 NN
现在,让我们看看与问题示例有什么区别。
假设你有 10 个实体(单词/句子/对象/任何东西),你有向量。
每个实体 1 个向量。
让我们考虑一下我们感兴趣的用于寻找邻居的指标是余弦相似度/余弦距离
这将形成多少对?大约 (10 * 9) / 2 = 45。
因此,您可以找到45 对之间的余弦相似度,然后找到您想要的 K-最近邻。很简单。这是您的 K-最近邻算法。
此外,鉴于您将这 45 个余弦相似度存储在某处,您基本上必须处理存储 45 个浮点数(余弦相似度可以在 -1 和 1 之间)。
现在,让我们扩大问题的规模。如果不是有 10 个实体,而是有 10,000,000 个,即 10M 个实体,该怎么办。在现实世界中存在这么多实体非常容易。
现在,您需要找到 (10M * (10M-1) / 2) = 4,99,99,99,50,00,000 对之间的余弦相似度。这是一个巨大的数字!基本上,复杂度随着 O(n^2) 的增加而增加,其中 n 是实体的数量。
现在,考虑为任何给定实体寻找 K 近邻。您还将为其运行 10M 相似度的排序算法。另外,让我们再考虑一下存储。假设 1 个浮点数占用 64 位(或 8 个字节)。你需要多少存储空间来存储这么多对?
4,99,99,99,50,00,000 * 8 字节 ~ 364 TeraBytes!
获得这种大小的内存 (RAM) 几乎是不可能的。
因此,您了解我们在使用常规 K-NN 方法时遇到的问题。我们不希望计算所有对,并且很难存储这些对的距离并在运行时为任何实体计算真正的 K-最近邻。
这就是Approximate Nearest Neighbors出现的地方。这些说,鉴于您对问题的需求几乎总是只得到 K 最近的邻居,为什么还要计算任何给定实体与那些在附近出现的机会为零的实体的相似性?
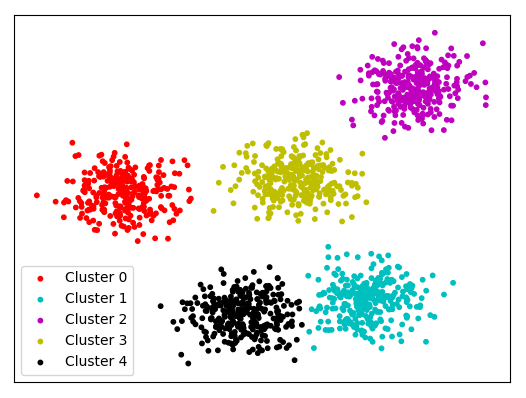
考虑一个有点簇的空间。假设您只需要为您的问题的每个点找到 3 个最近的邻居,那么您将永远不需要找到不同集群的点之间的相似性。对?
这就是 Approximate Nearest Neighbor 算法运行的理念。
对于任何给定的实体,它不会计算到每个其他点的相似度/距离,而是选择X个其他点并且只计算到这些点的距离。
这将复杂性从O(n 2 )降低到O(n*k)。存储变得更容易,计算变得更快。
Annoy 实现的提示
虽然我自己并不熟悉 Annoy 的 ANN 方法的所有实现细节。通常,大多数 ANN 方法需要首先构建一个集群索引——它基本上决定了X领导者,你会发现它们有相似之处。然后,使用聚类索引为所有给定点找到 Approximate K-nearest neighbors。
这被称为“近似”的原因是集群构建过程并不完美。如果是这样,它将需要数天或数年的计算,并且会破坏降低复杂性的目的。它是近似的集群指数。这意味着,有时您可能会错过出现在给定实体附近的最相似实体之一。但是,通常情况下,这种情况不会发生太多,以至于实际上会产生影响。Spotify、Facebook、谷歌和许多大公司正在使用近似最近邻方法。
Annoy 是用于进行近似最近邻的最广泛使用的库之一。
其它你可能感兴趣的问题