在少量图像上训练具有大量参数的 ConvNet 是如何工作的?
数据挖掘
神经网络
训练
卷积神经网络
2022-02-28 03:48:24
1个回答
首先,您忽略了问题的维度。图像非常高维。假设图像的分辨率为,这意味着每个图像都有像素。ImageNet 图像是 RGB,所以每张图像有 3 个通道,导致每个图像的像素。现在,整个数据集(m 图像)有超过十亿像素与其图像相关联。
因为过滤器在像素级工作,所以它从一张图像中获得的信息比常规 ML 算法从单个训练示例中获得的信息要多。
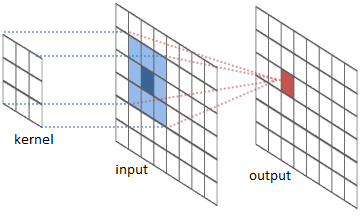
如您所见,内核(您要更新其权重,在本例中包含 9 个参数)比输入图像小得多。考虑单个图像(大约正如我们之前所说的像素)只能更新一个参数。
其次,由于网络的顺序性,每一层的输入随着层的变化而变化。第二层看到第一层的输出,依此类推……这意味着第二层的过滤器不会看到与第一层相同的图像,事实上,随着训练的进行,它们的输入也会逐渐变化(因为第一层的过滤器将变得更加有效)。
当它到达时,让我们说层,输入将与原始图像发生很大变化,因此认为原始图像正在更新网络中参数的整体是错误的。
第三,数据增强也是一回事。通过对每张图像进行简单的随机变换(翻转、移位、缩放、旋转、亮度/对比度调整等),网络被欺骗认为这是一张全新的图像。这可以成倍地增加数据集的大小。
最后,您应该看看网络中的参数在哪里。VGG19 架构确实有超过万,但大约其中 m 来自最后 3 个 FC 层。事实上,三层中的第一层大约有米参数自己!这是一种非常低效的网络设计,研究界最近才偏离了方向。您应该查看的更具代表性的网络是 ResNet 架构。例如,一个 50 层的 ResNet(比 19 层的 VGG 深得多)由大约m 个参数,同时实现类似的(如果不是更好的话)性能。
其它你可能感兴趣的问题