免责声明:这个答案不完整,但我现在没有时间让它成为最新的。我希望这周晚些时候能解决这个问题。
问题:
解决从 1969 年左右的数据进行预测的一般问题的最先进方法是什么?
注意:这不会重复“Matt Krause”的出色回答。
“最先进”的意思是“最好和最现代的”,但不一定要简化为行业规范。相比之下,美国专利法寻找由“本领域普通技术人员”定义的“非显而易见”。1969 年的“最先进技术”很可能在接下来的十年中获得专利。
1969 年的“最好和最聪明”的方法极有可能被用于或评估用于 ECHELON (1) (2)。它还将在评估另一个时代的数学能力很强的超级大国苏联时表现出来。(3) 我需要几年时间来制造一颗卫星,因此人们也期望未来 5 年的通信、遥测或侦察卫星的技术或内容能够展示 1969 年的最新技术。一个例子是Meteor-2 气象卫星始于 1967 年,初步设计于 1971 年完成。 (4) 光谱学和光度学有效载荷工程受到当时的数据处理能力以及当时设想的“近期”数据处理的影响。此类数据的处理是寻找该时期最佳实践的地方。
对“优化理论与应用杂志”的细读已经运行了几年,并且其内容可以访问。 (5) 考虑这个(6)对最优估计器的评估,以及这个用于递归估计器的评估。(7)
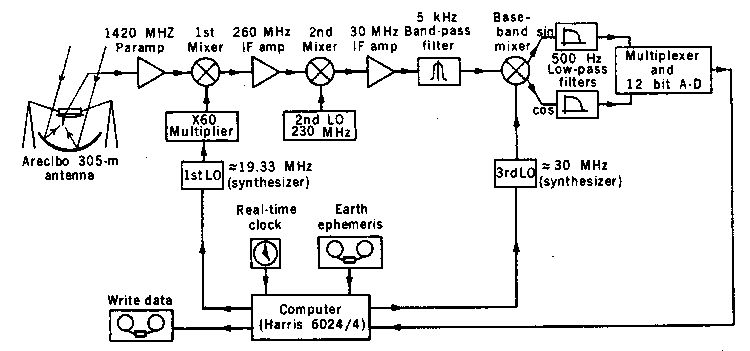
始于 1970 年代的 SETI 项目可能使用了较低预算的技术和较旧的技术以适应当时的技术。对早期SETI 技术的探索也可以说明 1969 年左右被认为是领先的技术。一个可能的候选者是“手提箱 SETI ”的先驱。“手提箱 SETI”使用 DSP 在约 130k 窄带通道中构建自相关接收器。SETI 的人特别希望进行频谱分析。该方法首先用于离线处理 Aricebo 数据。它后来在 1978 年将它连接到 Aricebo 射电望远镜以获取实时数据,并于同年公布了结果。实际的 Suitecase-SETI 于 1982 年完成。这里(链接)
该方法是使用离线长傅里叶变换(约 64k 样本)来搜索带宽段,包括处理啁啾和多普勒频移的实时补偿。该方法“不是新的”,提供的参考资料包括:例如,参见
A. G. W. Cameron, Ed.,
In- terstellar Communication
(Benjamin, New York,1963);
I. S. Shklovskii and C. Sagan,
In-telligent Life in the Universe
(Holden-Day, San Francisco, 1966);
C. Sagan, Ed.,
Communication with Extraterrestrial Intelligence
(MIT Press, Cambridge, Mass., 1973);
P. Morrison, J.
B. M. Oliver and J. Billingham,
"Project Cyclops: A Design Study of a System for Detecting Extraterrestrial Intelligent Life,"
NASA Contract. Rep. CR114445 (1973).
在当时流行的给定先前状态的情况下,用于预测下一个状态的工具包括:
- 卡尔曼(和导数)滤波器(Weiner、Bucy、非线性...)
- 时间序列(和衍生)方法
- 频域方法(傅立叶),包括滤波和放大
常见的“关键词”(或流行语)包括“伴随、变分、梯度、最优、二阶和共轭”。
卡尔曼滤波器的前提是真实世界数据与分析和预测模型的最佳混合。它们被用来制造诸如导弹击中移动目标之类的东西。
{kind=link}