对于 LogisticRegression,我在 python 2.7(本地机器)和 python3(在 kaggle 上运行的系统)上的相同内核有不同的结果。怎么可能?
这是我本地机器的结果:
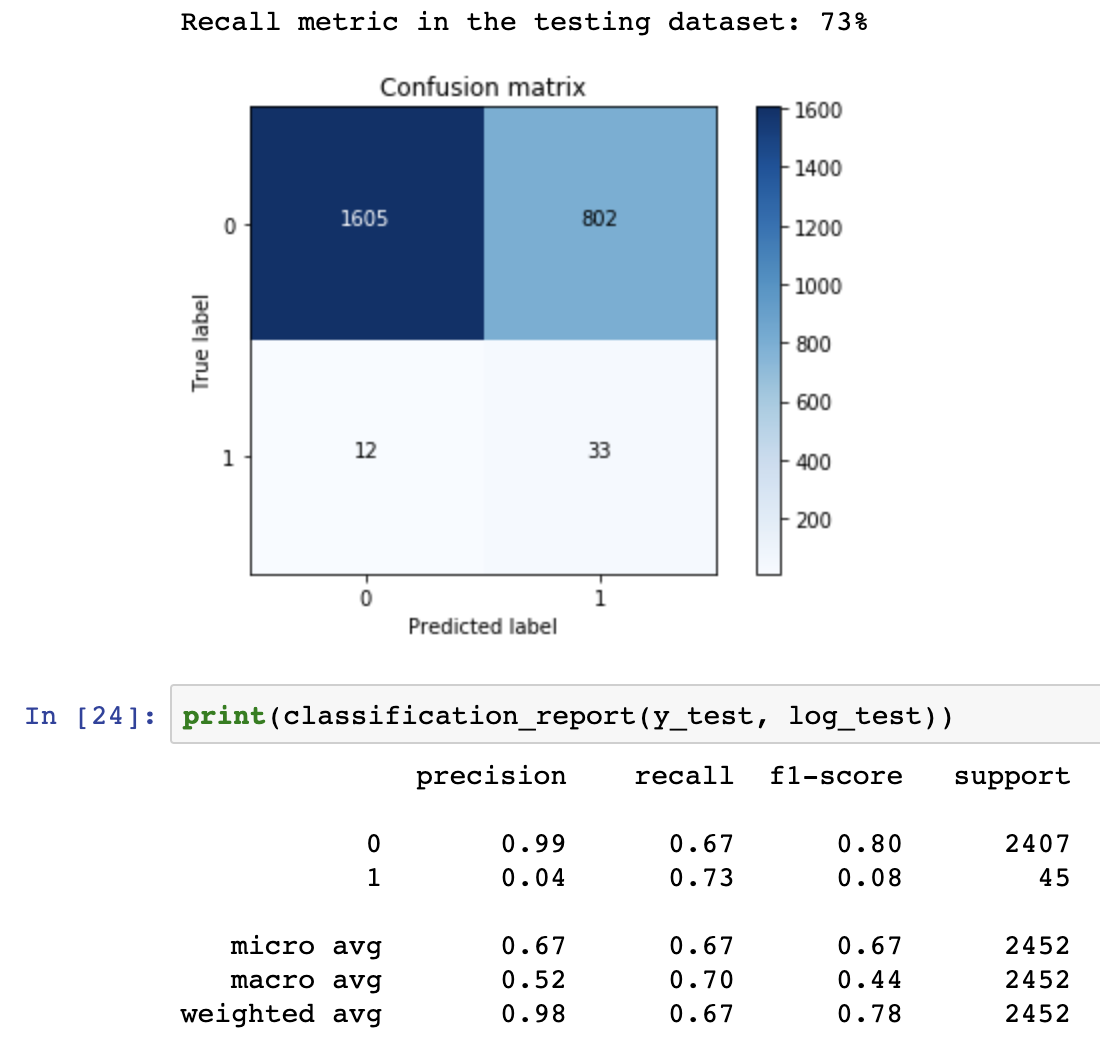
这里来自 kaggle 笔记本:
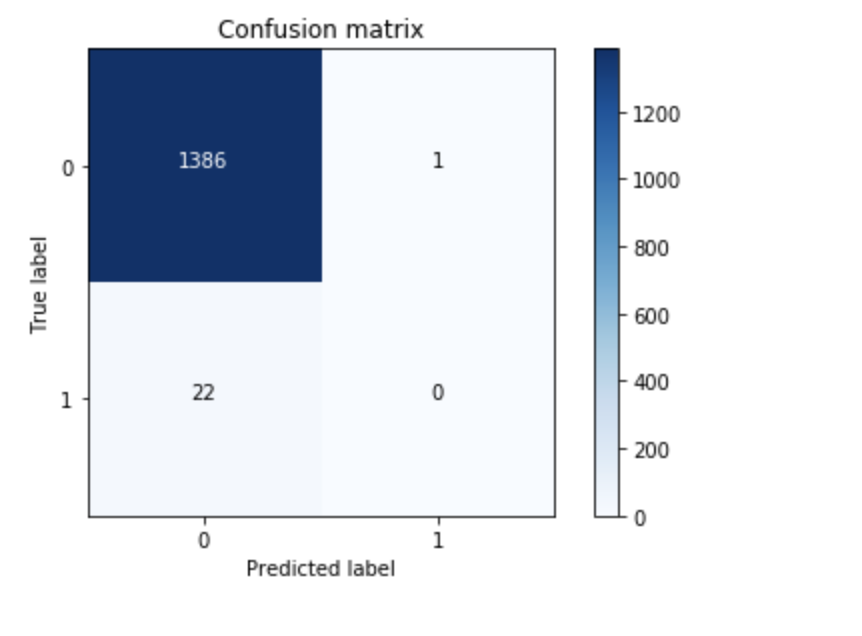
数据量不同,因为我对训练数据进行了更多拆分,但预测完全不同。这可能是因为python的版本吗?
对于 LogisticRegression,我在 python 2.7(本地机器)和 python3(在 kaggle 上运行的系统)上的相同内核有不同的结果。怎么可能?
这是我本地机器的结果:
这里来自 kaggle 笔记本:
数据量不同,因为我对训练数据进行了更多拆分,但预测完全不同。这可能是因为python的版本吗?
假设您使用的是 sklearn,如果您转到github中的源代码, 您会发现它们没有区别。
但是你在其他地方有可变性。例如,sklearn 的 train_test_split 也采用随机种子,因此这些方法之间的数据可能存在根本不同(例如,您可以进行交叉验证以将所有数据包含在训练和测试中)
主要问题是序数数据转换。Python 2.7 以某种方式检测到序数数据并使用它。在 python3 中,我必须将序数数据转换为:
from sklearn.preprocessing import OrdinalEncoder
encoder = OrdinalEncoder()
train_df.F1 = encoder.fit_transform(train_df.F1.values.reshape(-1, 1))
现在它也适用于 python3 !