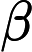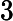我试图了解如何最好地模拟一个变量,随着时间的推移,我获得了越来越详细的预测变量。例如,考虑对违约贷款的回收率进行建模。假设我们有一个包含 20 年数据的数据集,而在前 15 年中,我们只知道贷款是否被抵押,但对抵押品的特征一无所知。然而,在过去五年中,我们可以将抵押品分为一系列类别,这些类别有望很好地预测回收率。
鉴于此设置,我想为数据拟合模型,确定预测变量的统计显着性等度量,然后使用模型进行预测。
这适合哪些缺失的数据框架?是否有任何特殊考虑与更详细的解释变量仅在给定时间点之后才可用这一事实相关,而不是分散在整个历史样本中?