我知道随机森林使用 Bagging,但是集成如何在sklearnBagging 与随机森林中给出单一预测?另外,我不明白为什么在 Bagging 中不需要选择树估计器,而在 RF 中不需要?除此之外,其他步骤是否相同?sklearnBagging 与随机森林的主要实现差异是什么?
如果您有“像我 5 岁一样解释”的简单示例,请使用sklearn请加分。
我知道随机森林使用 Bagging,但是集成如何在sklearnBagging 与随机森林中给出单一预测?另外,我不明白为什么在 Bagging 中不需要选择树估计器,而在 RF 中不需要?除此之外,其他步骤是否相同?sklearnBagging 与随机森林的主要实现差异是什么?
如果您有“像我 5 岁一样解释”的简单示例,请使用sklearn请加分。
我们可以使用“Iris”数据集来演示Bagging和随机森林
首先,让我们看一下Iris数据集:
做例子 sklearn,我们需要导入通常的嫌疑人......
from sklearn.datasets import load_iris
from sklearn.ensemble import BaggingClassifier, RandomForestClassifier
import pandas as pd
iris = load_iris()
y= pd.Series(iris.target)
然后我们指定我们将使用两个 ML 模型中的哪一个:
# create Ensemble object/instance
model = BaggingClassifier(base_estimator=None)
model = RandomForestClassifier()
无论我们使用哪两个,我们的sklearn步骤都是一样的:
# Train the model using the training sets
model.fit(X_train, y_train)
# OUTPUT
## check score
model.score(X_train, y_train)
## Predict on test set
predicted= model.predict(X_test)
为了直观全面地展示 Bagging 投票†,WLOG 我们有一个简化版的“Iris”数据集有:
sklearn总是需要数字输入,所以它们的sklearn数字标签
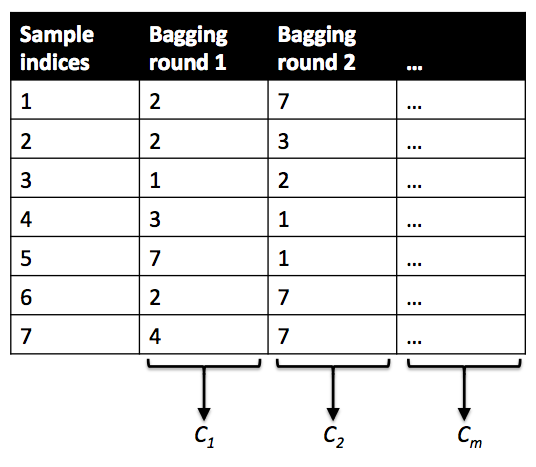
for我们的 7 观察简化“虹膜”训练数据集,我们:
取5 个 Bootstrap 样本
每个 Bootstrap 样本的基数为 7,从我们简化的“虹膜”数据集中选择替换
即,每个引导样本有 7 个可能重复的观察值
然后在第 2 步中,我们训练:
在每个 Bootstrap 样本上训练一个不同的决策树分类器
在每个 Bootstrap 样本上训练一个不同的随机森林决策树分类器
所以我们最终得到了一个由总共 5 个决策树分类器组成的 Bootstrap-samples-aggregated 集合,这些分类器在 Bagging 的情况下是完全增长的,或者在随机森林的情况下是使用特征子集增长的。
for一个测试集X_test由一朵以前看不见的花组成:
if5 个单独的子估计树的输出是: predict_probasklearn
然后任何一个 Bootstrap-samples-aggregating meta-estimators' Test-set predict = A)on this specific flower-sample
A)Bagging 或随机森林元估计器分类为物种sklearn的 Bootstrap-samples-aggregating分类元估计器都有一种predict方法,其平均过程returns是具有最高平均预测概率的类
† (并且还能够使用我在互联网上找到的图像)
◊这个(荒谬的)7数据点“鸢尾花”数据集仅用于解释目的
不同之处在于两者的节点级别拆分。因此,使用决策树的 Bagging 算法将使用所有特征来决定最佳分割。另一方面,在随机森林中构建的树使用每个节点的随机特征子集来决定最佳分割。