在此处查看本段:http: //www.chioka.in/differences-between-l1-and-l2-as-loss-function-and-regularization/
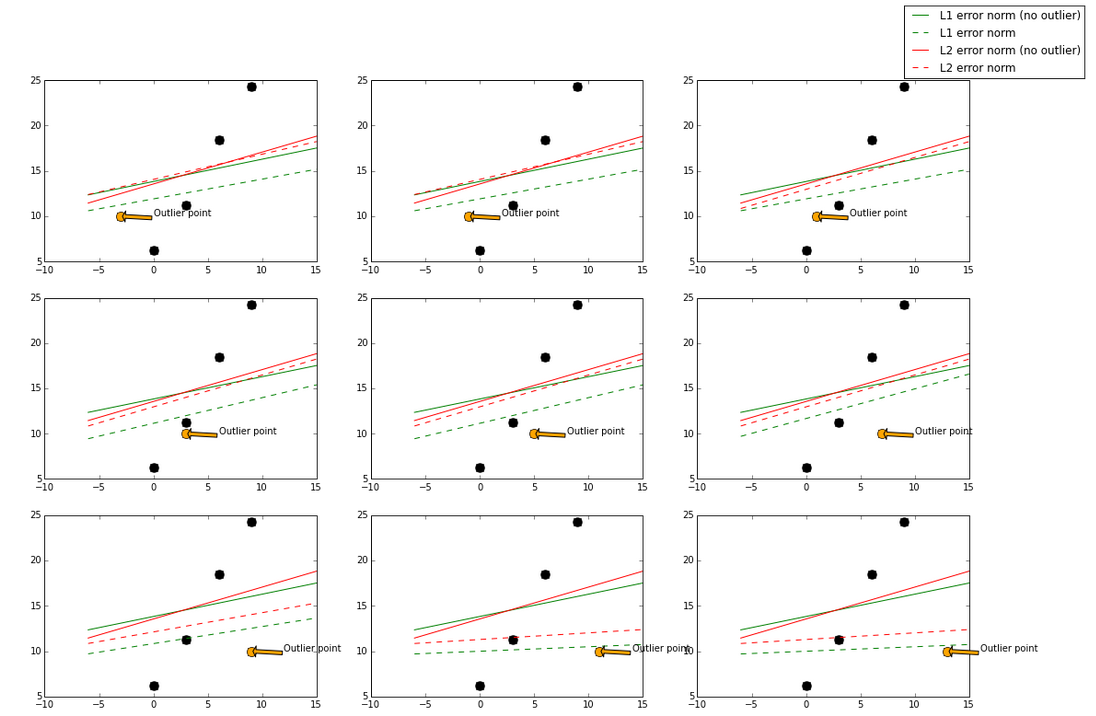
最小绝对偏差法的不稳定性意味着,对于一个基准面的一个小的水平调整,回归线可能会有很大的跳跃。该方法对某些数据配置有连续解;但是,通过少量移动基准,可以“跳过”具有跨区域的多个解决方案的配置。在通过这个解的区域后,最小绝对偏差线的斜率可能与前一条线的斜率有很大不同。相反,最小二乘解是稳定的,因为对于数据点的任何小的调整,回归线总是只会轻微移动;也就是说,回归参数是数据的连续函数。
出于某种原因,我在网上找不到任何描述这种“稳定”现象的东西。它以不同的名称而闻名吗?
稳定性似乎指的是,对于 (x,y) 数据集,“稍微微调单个输入 x_i。对于 L1 目标函数,预测线的斜率会发生巨大变化,因此 L1 目标是不稳定的。”
我真的很想对该帖子中包含的这张图片进行理论解释:http: //www.chioka.in/wp-content/uploads/2013/12/programmatic-L1-vs-L2-visualization.png
{kind=link}