http://yann.lecun.com/exdb/mnist/
像素值为 0 到 255。0 表示背景(白色),255 表示前景(黑色)。
原件mnist将背景设置为低值 (0) 并将前景设置为最高值 (255) 是否有原因?
在同一个 convnet 上进行训练时,反转这些值会对性能产生影响吗?(这个评论有意义吗)
还是只是为了加快训练速度,因为大多数图像在mnist字符上设置为 0?
http://yann.lecun.com/exdb/mnist/
像素值为 0 到 255。0 表示背景(白色),255 表示前景(黑色)。
原件mnist将背景设置为低值 (0) 并将前景设置为最高值 (255) 是否有原因?
在同一个 convnet 上进行训练时,反转这些值会对性能产生影响吗?(这个评论有意义吗)
还是只是为了加快训练速度,因为大多数图像在mnist字符上设置为 0?
这是tensorflow 教程中mnist_softmax实现的快速测试。您可以将此代码附加到文件末尾以重现结果。
在 MNIST 输入数据中,像素值范围从 0(黑色背景)到 255(白色前景),通常在 [0,1] 区间内缩放。
在 tensorflow 中, 的实际输出mnist.train.next_batch(batch_size)确实是该格式的训练数据的 (batch_size, 784) 矩阵。现在让我们反转灰度,通过 batch_xs = 1-batch_xs. 我们现在可以用正常和反转输入数据的分类准确度来衡量性能,并在 100 次试验中平均该准确度,在每次试验中我们对神经网络执行 50 次更新。
n_trials = 100
n_iter = 50
accuracy_history = np.zeros((2,n_trials))
batch_size = 100
for k, preprocessing in enumerate(['normal','reversed']):
sess.run(init)
for t in range(n_trials):
for i in range(n_iter):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
if preprocessing == 'reversed':
batch_xs = 1-batch_xs
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
images = mnist.test.images
if preprocessing == 'reversed':
images = 1-mnist.test.images
accuracy_history[k,t] = sess.run(accuracy, feed_dict={x: images,
y_: mnist.test.labels})
print(accuracy_history.mean(axis=1))
>> Out[58]: array([ 0.91879 , 0.837478])
要回答您的问题,反转灰度值确实会影响性能。
我相信数据中心化是黑底白字表现不如黑底白字的原因之一。一般来说,在机器学习中,将数据归一化是一种很好的做法。当您想到 MNIST 数据集时,图像上的大多数像素都是黑色的,因此平均值接近 0,而如果您将其反转,它将为 1(如果不按比例缩小,则为 255)。
更重要的是,在神经网络更新中,输入中对应于 0 的权重不会被更新。您可以通过观察训练后神经网络权重的演变(分别为 W_begin 和 W_end)通过实验看到它。下面是两个表示权重绝对值变化的热图。
from matplotlib.pyplot import imshow
heatmap = (np.abs(W_begin-W_end).max(axis=1)).reshape((28,28))
imshow(heatmap)
对于第一个图像 - 黑色数字上的白色 - 您可以看到图像边框(深蓝色)上的权重根本没有改变。
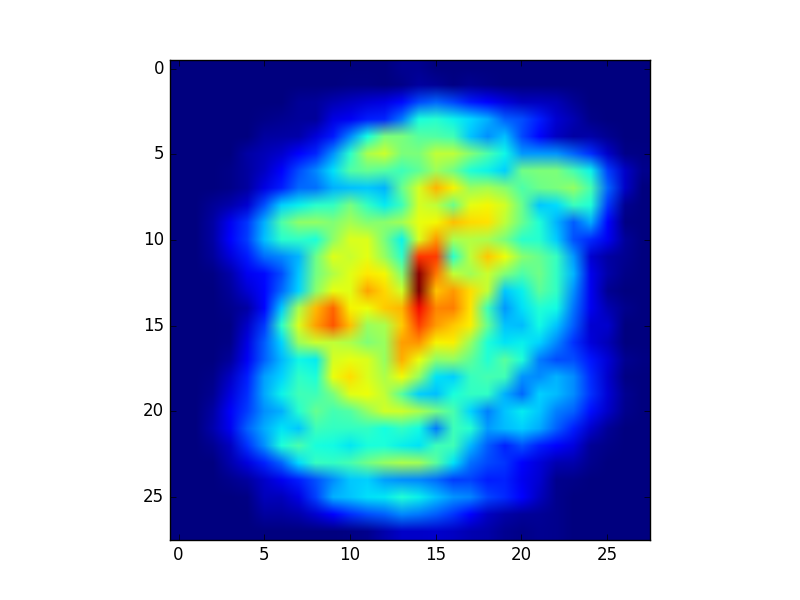
然而,在第二张图片上——白色数字上的黑色——你可以看到边框上有一个更亮的蓝色,这意味着这些权重发生了变化。但是您也会注意到图像中心附近的深蓝色区域,这表明该区域的权重没有太大变化。
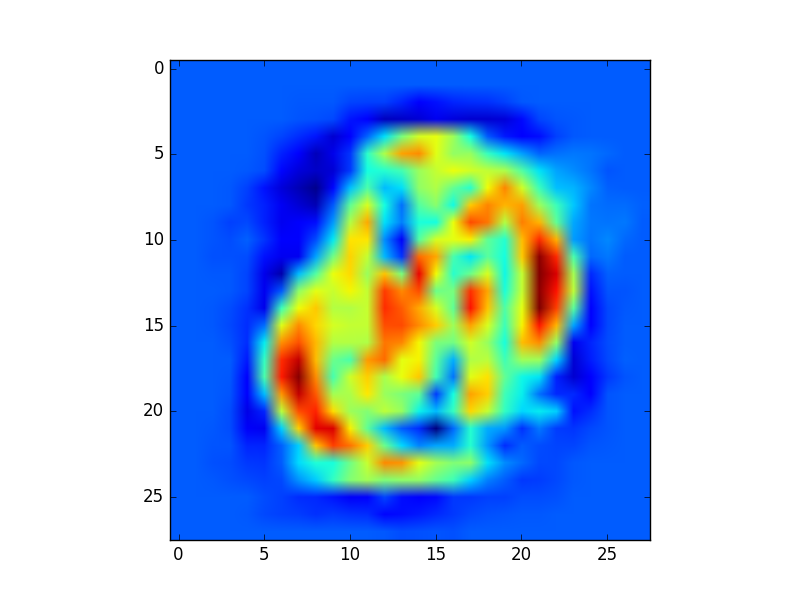
直观地说,我们并不关心更新边界的权重,因为相应的像素不会区分不同类别的数字。但是,出于相反的原因,我们确实关心图像中间的权重。这解释了为什么黑底白字 MNIST 比黑底白字表现得更好。