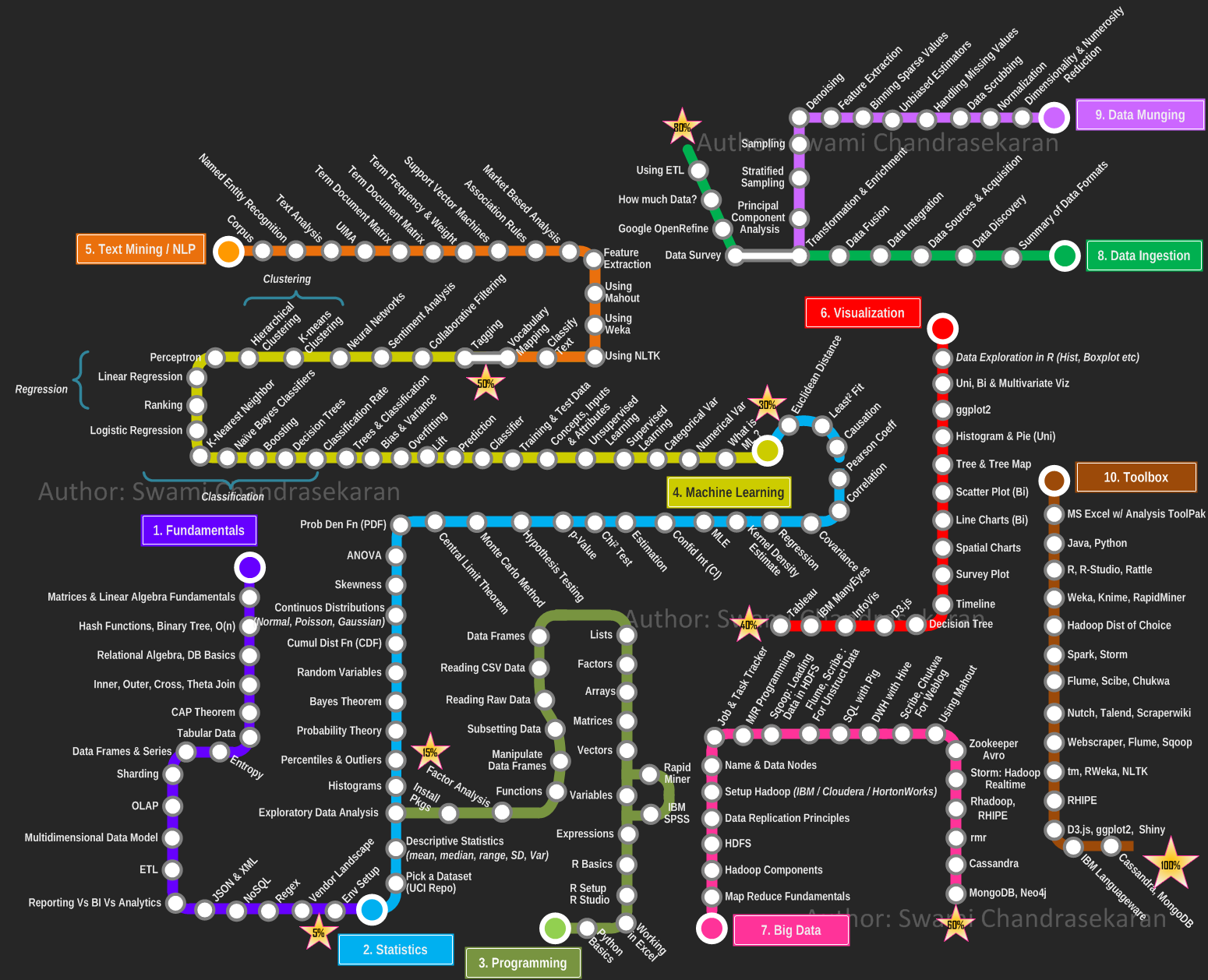
数据科学与机器学习有何关系?
数据科学是比机器学习更广泛的概念。它从简单的数据可视化和描述性统计开始,以获得洞察力,通过清理等操作来准备数据。在您可以使用一些 ML 算法之前。
基本上,像大数据、可视化和数据预处理这样的巨大堆栈超出了机器学习的范围。它们都是“数据科学”的组成部分。
大分辨率图片: https ://whatsthebigdata.files.wordpress.com/2013/07/datascientistmap.png
{kind=link}
机器学习试图创建可以从数据中学习的系统。因此,它可以用于各种设置,例如让机器人学会走路或训练虚拟代理玩视频游戏。
数据科学本身关注从数据中提取知识。为了做到这一点,它使用了来自不同学科的大量不同技术。机器学习包括一些对数据科学家非常有用的技术,例如深度学习、决策树和不同的聚类算法。然而,机器学习提供的不仅仅是数据科学的用途,而且数据科学不仅仅依赖于机器学习。
数据科学的范围要广泛得多。这是一个包罗万象的术语,现在还没有一个非常明确的定义。但是数据科学包括理解数据所需的所有技能和技术,这些数据具有高速度(它很快就会向你袭来)、大量(有很多)或可变性(它很混乱,就像自然语言处理一样)。这意味着它当然包括机器学习和人工智能,但它也涉及人们可能在现实世界中使用的工具,例如 SQL、Hadoop 或 Spark(以及相关信息,例如并行编程知识)。此外,数据科学可能包括也可能不包括通信方面,例如制作好的图表和使用 Excel。
基本上,数据科学是 ML+。
正如其他人所指出的,数据科学是一个比机器学习更广泛的术语。应用机器学习技术是数据科学的一个方面。更一般地说,数据科学是从数据中获取知识的科学。该术语是在 1960 年创造的,并不断发展以描述问题定义、数据收集、数据转换、数据建模/分析和决策制定的流程和相互作用。因此,具体回答您的问题:
- 机器学习通过提供一套用于数据建模/分析的算法(通过机器学习算法的训练)、决策制定(通过流式传输、在线学习、实时测试,这些都是机器学习的主题)来帮助数据科学,以及甚至数据准备(机器学习算法自动检测数据中的异常)。
- 数据科学将一堆从机器学习中提取的想法/算法拼接在一起,以创建一个解决方案,并在此过程中借鉴了许多来自传统统计学、领域专业知识和基础数学的想法。通过这种方式,数据科学是解决用例的过程,提供解决方案,而不是机器学习,机器学习是该解决方案中的重要组成部分。