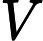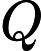我正在努力理解演员评论家和优势演员评论家之间的区别。
至少,我知道它们与异步优势 actor-critic (A3C) 不同,因为 A3C 添加了一种异步机制,该机制使用多个工作代理与他们自己的环境副本交互并将梯度报告给全局代理。
但是演员评论家和优势演员评论家(A2C)之间有什么区别?它只是有或没有优势功能吗?但是,那么,除了使用优势函数之外,actor-critic 还有其他实现吗?
或者它们是同义词吗?actor-critic 只是 A2C 的简写?
我正在努力理解演员评论家和优势演员评论家之间的区别。
至少,我知道它们与异步优势 actor-critic (A3C) 不同,因为 A3C 添加了一种异步机制,该机制使用多个工作代理与他们自己的环境副本交互并将梯度报告给全局代理。
但是演员评论家和优势演员评论家(A2C)之间有什么区别?它只是有或没有优势功能吗?但是,那么,除了使用优势函数之外,actor-critic 还有其他实现吗?
或者它们是同义词吗?actor-critic 只是 A2C 的简写?
Actor-Critic 不仅仅是一个单一的算法,它应该被视为相关技术的“家族”。它们都是基于策略梯度定理的技术,它训练某种形式的批评者,该批评者计算某种形式的价值估计,以插入更新规则,作为剧集结束时回报的低方差替代。他们都通过使用某种价值预测来执行“引导”。
Advantage Actor-Critic专门使用优势函数的估计因为它的引导,而没有“advantage”限定词的“actor-critic”并不具体;它可能是受过训练的函数,它可能是某种估计,它可能是各种各样的东西。
在实践中,Advantage Actor-Critic 方法的批评者实际上可以被训练来预测. 结合经验观察到的奖励,然后他们可以计算优势估计.
根据 Sutton 和 Barto 的说法,它们是一回事。Note 13.5-6 (page 338) of their Reinforcement Learning: An Introduction, 2nd Edition book:
Actor-critic 方法在文献中有时被称为优势 Actor-Critic 方法
尽管在actor-critic领域中的“优势”一词被用来指代状态值和状态动作值之间的差异,但A2C引入了A3C的思想。在 A3C 中,多个工作网络与环境的不同副本交互(异步学习),并在一组 if 步骤后更新主网络。这是为了解决与时间差异更新方法和神经网络生成的预测值和目标值之间的相关性相关的不稳定性问题。然而,OpenAI 注意到不需要异步,即拥有不同的工作网络没有实际好处。相反,他们拥有与环境的不同副本交互的相同网络副本(一个从一开始就起作用,另一个从最后开始向后工作)并且它们会立即更新,而不会像 A3C 中那样落后。消除异步导致了 A2C。