半监督学习和自我监督视觉表征学习有什么区别,它们是如何联系起来的?
半监督和自监督视觉表征学习之间有什么关系?
人工智能
机器学习
比较
监督学习
自监督学习
半监督学习
2021-10-21 21:52:44
3个回答
半监督和自我监督的方法都是相似的,因为目标是每个类使用更少的标签来学习。两者制定的方式完全不同:
- 自我监督学习:
这项工作旨在在不需要人工标注标签的情况下学习图像表示,然后将这些学习到的表示用于一些下游任务。例如,您可以获取数百万张未标记的图像,将它们随机旋转 0、90、180 或 270 度,然后训练模型来预测旋转角度。训练模型后,您可以使用迁移学习在猫/狗分类等下游任务上微调此模型,就像微调 ImageNet 预训练模型一样。您可以查看这些方法的概述,还可以查看当前提供最先进结果的对比学习方法,例如SimCLR和PIRL。
![]()
- 半监督学习
与自我监督学习不同,半监督学习旨在同时使用标记数据和未标记数据来提高监督模型的性能。这方面的一个例子是FixMatch论文,您可以在其中在标记图像上训练模型。然后,对于未标记的图像,您应用增强功能为每个未标记的图像创建两个图像。现在,我们要确保模型为未标记图像的增强预测相同的标签。这可以作为交叉熵损失并入损失中。
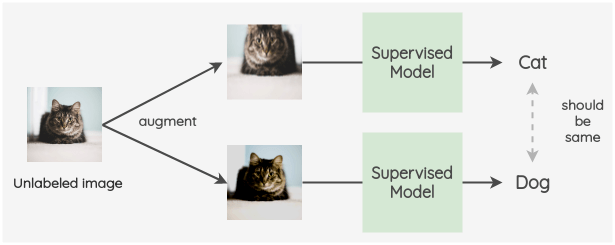
半监督学习
半监督学习是机器学习技术的集合,其中有两个数据集:一个标记的数据集和一个未标记的数据集。
使用半监督学习可以解决两个主要问题:
- 转导学习(即标记给定的未标记数据)和
- 归纳学习(泛化)(即找到一个将输入映射到输出的函数,如分类)。
自监督学习
自监督学习(SSL) 是一种自动生成监督信号的机器学习方法。更准确地说,SSL 既可以指
通过以自我监督的方式解决所谓的借口(或辅助)任务来学习数据表示(即学习表示数据),即您自动从未标记的信号中生成监督信号
通过利用来自不同传感器的数据自动标记未标记的数据集(这是 SLL 在上下文或机器人技术中的通常定义)
两者之间有什么关系?
SSL(用于数据表示)可以被认为是一种半监督学习方法,如果您使用标记数据集微调学习的数据表示以解决监督学习问题(即所谓的下游任务),否则您可能会这样做数据表示非常无用。阅读此答案以了解其他详细信息。
先前的答案很好地了解了两个领域之间的区别。我想举更多的例子。
半监督学习通过添加新示例来改进数据集。在迭代系统中,我们在给定数据集上训练模型,并在将模型部署到现实世界后通过添加现实世界及其结果的交互来进一步改进模型,以进一步训练系统。
如今,自我监督学习正成为一个非常热门的话题。它能够通过某种监督信号(不完全是标签)来理解给定数据集的下划线属性。Transformers 中引入的self-Attention是一种现代流行的自我监督学习。另外,查看来自Yann Lecun 推文的这条推文
其它你可能感兴趣的问题