tl;博士
我发现最安全的方法是使用交叉验证来选择超参数,并使用保留测试集进行最终评估。
为什么这对你不起作用...
在您的情况下,我怀疑您要么在选择超参数期间运行大量迭代,要么您的数据集相当小(甚至两者兼而有之)。如果您找不到更多数据或使用更大的数据集,我建议限制超参数选择阶段的详尽性。如果您运行该过程足够多次,则模型必然会在验证集上过拟合。
请注意,在测试集之前没有保证检测过拟合的安全方法!
为什么我认为这种策略是最安全的
您需要能够检测两种不同类型的过拟合。
第一个是最直接的:在训练集上过拟合。这意味着该模型已经记住了训练集,并且无法进行泛化。如果测试集与训练集略有不同(这是大多数现实世界问题的情况),那么模型在它上的表现将比在训练集上更差。这很容易检测,事实上,您唯一需要捕获的就是测试集!
您需要检测的第二种过度拟合是在测试集上。想象一下,您有一个模型,并且您使用测试集进行了详尽的超参数选择。然后你在同一个测试集上进行评估。通过这样做,您已经调整了超参数以获得特定测试集的最佳分数。因此,这些超参数过度拟合该测试集,即使该集的样本在训练期间从未见过。这是可能的,因为在迭代超参数选择过程中,您已将有关测试集的信息传递给模型!
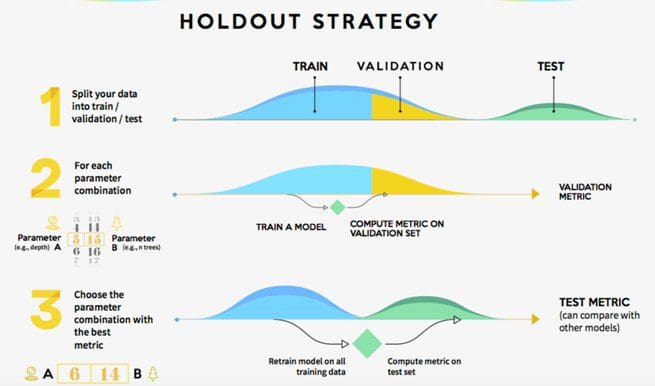
这更难检测。事实上,这样做的唯一方法是将原始数据分成三部分:训练集、验证集和测试集。第一个用于训练模型,第二个用于超参数选择,最后一个用于最终评估。如果你的模型已经过拟合(即测试性能比训练和验证差),你需要从头开始。随机播放您的数据,再次拆分并重复该过程。这通常被称为保持策略。
为了使模型更不容易过度拟合,您可以使用交叉验证而不是保留验证集。因为你的模型现在必须接受训练k略有不同的训练集和评估k完全不同的验证集,它很难在验证集上过拟合(因为它需要欺骗 k不同的验证集而不是一个)。
这可能不适用的情况
根据具体情况,应用这两种技术可能不切实际。
交叉验证在过度拟合方面非常稳健,但它给您的过程带来了计算负担,因为它需要对同一模型进行多次训练。这对于计算量大的模型(例如图像分类器)显然是不切实际的。在这种情况下,请使用前面提到的保留策略。
使用保留测试集意味着您正在减少训练集的大小,这实际上可能使您的模型更容易过度拟合(即具有更高的方差)小数据集。在这种情况下(如果您的模型由于体积小而实际上无法训练),您可以求助于交叉验证,但您可能会在验证集上过度拟合并且无法检测到它。
如何对抗过拟合
由于它是相当相关的,我将发布一个关于如何对抗过度拟合的答案的链接。
{kind=link}