在论文Deterministic Policy Gradient Algorithms中,我对第 4.1 章和第 4.2 章感到非常困惑,即“On and off-policy Deterministic Actor-Critic”。
我不知道两种算法有什么区别。
我只注意到方程 11 和 16 不同,不同之处在于 Q 函数的作用部分在等式 11 和在等式 16 中。如果这真的很重要,我该如何计算在等式 11 中?
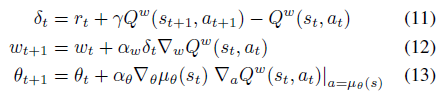
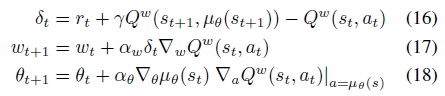
在论文Deterministic Policy Gradient Algorithms中,我对第 4.1 章和第 4.2 章感到非常困惑,即“On and off-policy Deterministic Actor-Critic”。
我不知道两种算法有什么区别。
我只注意到方程 11 和 16 不同,不同之处在于 Q 函数的作用部分在等式 11 和在等式 16 中。如果这真的很重要,我该如何计算在等式 11 中?
这里的转折是在 (11) 和在 (16) 中是相同的,实际上在 on-policy 的情况下和在off-policy的情况下是不同的。
理解的关键在于,在策略算法中,您必须使用策略在更新步骤中生成的动作(以及一般来说的轨迹)(以改进策略本身)。这意味着在 on-policy 情况下(在等式 11-13 中)。
而在非策略情况下,您可以使用任何轨迹来改进您的价值/行动价值函数,这意味着行动可以由任何分布生成. 然而,在 (16) 中,算法明确指出动作值函数 () 必须在(就像在 on-policy 案例中一样)而不是在这是政策产生的轨迹中的实际行动.
on-policy 和 off-policy 的主要区别在于如何获取样本以及我们优化什么策略。
在 off-policy 确定性 actor-critic 中,轨迹是来自 beta 分布的样本(也称为行为策略),而不是我们优化的策略(即)。然而,在 on-policy actor-critic 中,行动从目标策略中采样我们优化的策略也是.