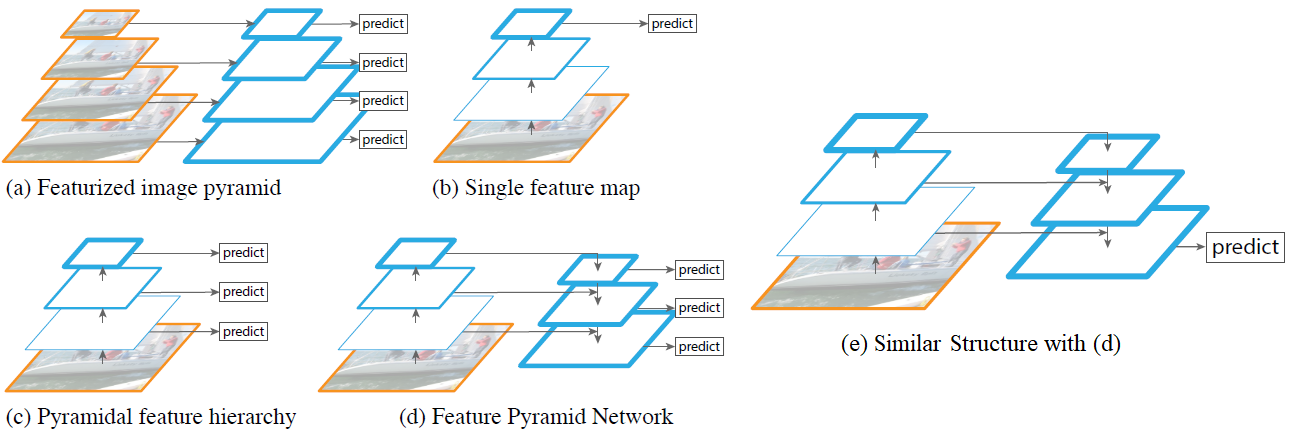
所以YOLO V3和RetinaNet都使用看起来像这样的特征金字塔:( 除了b有e一个输出)
b
e
我只是混淆了预测和训练是如何完成的?我们必须给每个特征图一个不同的Y label吗?如果是,那怎么可能?在我看来,我们需要有N不同的基本事实。(我认为还会有 3 种不同的损失?)
Y label
N
如果没有,那么这些如何一次完成?
这些网络存在很多混乱,因为我无法理解 YOLOv3 和 RetinaNet 中如何提供、训练和预测 y 标签。如果我知道这一点,那么关于损失、多输出等一切都会变得有意义。