我有一个如下所示的音频频谱 (FFT):
101761.00 : *
76309.98 :
57224.41 :
42912.26 : * * *
32179.65 : * *
24131.34 : * * *
18095.95 :
13570.05 : * * *
10176.10 : * * *
7631.00 : * *
5722.44 : * * *
4291.23 : * * ** * ** *
3217.97 : * * *
2413.13 : * * *
1809.59 : * * * * * * *
1357.00 : *** ** * *
1017.61 : * ** * * * **
763.10 : * * * ** * * **
572.24 : * * * * * ** * * *
429.12 : * * * * * * *
321.80 : * * * *
241.31 : * * * ** * * * * *
180.96 : * * * * * * * * * ** * * * *
135.70 : ** * * * * * * *
101.76 : * * * * * * * * * * * * * *
76.31 : * * * *
57.22 : * * * * * *
42.91 : * * * *** ** * * * * *
32.18 : * * * ** * ** ** * * * ** * *
24.13 :
18.10 : * ** * * *** * ***** * * * * *** * *
13.57 :
10.18 : * * * * *** * * ** ** ** ** * * * * * ** * *
7.63 :
5.72 :
4.29 : * * * * * * *** *** ** * * * * * ** ** * * ****
3.22 :
2.41 :
1.81 :
1.36 : * * * * ** **** * * * ** * * * ** ********* ****************** ** ** **
========= : ======================================================================================================================================================
: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
: 0 0 0 1 1 1 2 2 2 3 3 3 4 4 5 5 5 6 6 6 7 7 7 8 8 8 9 9 9 0 0 0 1 1 1 2 2 2 3 3 3 4 4 4 5 5 6 6 6 7 7 7 8 8 8 9 9 9 0 0 0 1 1 1 2 2 2 3 3 3 4 4 4 5 5
: 1 5 8 2 5 8 2 5 9 2 6 9 3 6 0 3 6 0 3 7 0 4 7 1 4 7 1 4 8 1 5 8 2 5 8 2 5 9 2 6 9 3 6 9 3 6 0 3 7 0 4 7 0 4 7 1 4 8 1 5 8 1 5 8 2 5 9 2 6 9 2 6 9 3 6
: 7 2 6 1 5 9 4 8 3 7 2 6 1 5 0 4 8 3 7 2 6 1 5 0 4 9 3 7 2 6 1 5 0 4 9 3 8 2 6 1 5 0 4 9 3 8 2 7 1 5 0 4 9 3 8 2 7 1 6 0 4 9 3 8 2 7 1 6 0 4 9 3 8 2 7
基本上,在 500Hz 附近有一个较宽的峰值,在 1750Hz 附近有一个较窄的峰值。很明显,数据中有很多噪音。(对于那些感兴趣的人来说,这是一个鼾声。)
不同的人具有相似的频率分布,只有峰值可以按比例放大/缩小(可能基于喉咙和嘴巴的共振频率)。
如何将其与分布更随机的不同声音区分开来?例如,在一个实例中,令人窒息的声音看起来像这样:
339889.00 : **
254880.80 :
191133.62 :
143330.00 : *
107482.34 : *
80600.38 : *
60441.76 : *
45324.93 : * *
33988.90 : * * *
25488.08 : * * * * *
19113.36 : * **
14333.00 : * * * * *
10748.23 : * *
8060.04 : * * * **
6044.18 : *** * * * * *
4532.49 : ** * * * *
3398.89 : * * * ** * *
2548.81 : * * * * * * *
1911.34 : * * * * *
1433.30 : * * * * * * * * *
1074.82 : * * * * * * * *
806.00 : * * ** * ***
604.42 : * * * * ** * * *
453.25 : * * * * * * * ** *
339.89 : * * * * * * * * * * * * * *
254.88 : * * ** * * *** * *
191.13 : * * * * * ** ** *
143.33 : * * *
107.48 : * * * * * * * * * * ** * * *
80.60 : * * * * * *
60.44 : * * * * * * ** * * * ** *
45.32 : * * *** * * * ** * * * * *
33.99 :
25.49 : * * * * * * * * * ** * * * * *
19.11 : * * * * * * * * *** * *** * * * *
14.33 :
10.75 : * * * * * * * * * * * * * * * * ** ** * *
8.06 :
6.04 :
4.53 : *** * * * * * * * ** * * * *** * **** * * ********** ** ***** **** ***** *** *******
========= : ======================================================================================================================================================
: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
: 0 0 0 1 1 1 2 2 2 2 3 3 3 4 4 4 5 5 5 6 6 6 7 7 7 7 8 8 8 9 9 9 0 0 0 1 1 1 2 2 2 2 3 3 3 4 4 4 5 5 5 6 6 6 7 7 7 7 8 8 8 9 9 9 0 0 0 1 1 1 2 2 2 2 3
: 1 4 7 0 4 7 0 3 6 9 2 5 9 2 5 8 1 4 7 0 4 7 0 3 6 9 2 5 9 2 5 8 1 4 7 0 4 7 0 3 6 9 2 5 9 2 5 8 1 4 7 0 4 7 0 3 6 9 2 5 9 2 5 8 1 4 7 0 4 7 0 3 6 9 2
: 6 7 8 9 1 2 3 4 6 7 8 9 1 2 3 4 6 7 8 9 1 2 3 4 6 7 8 9 1 2 3 4 6 7 8 9 1 2 3 4 6 7 8 9 1 2 3 4 6 7 8 9 1 2 3 4 6 7 8 9 1 2 3 4 6 7 8 9 1 2 3 4 6 7 8
正如你所看到的,它有点杂乱无章(如果可能的话),至少在某些情况下更“尖峰”,而且,看起来,再现性要差得多——下一个声音会有点不同,而打鼾往往看起来很相似(至少站在 10 英尺后)。
我可以看到通过将声音分成多个频段并给每个频段打分来尝试识别,然后提出诸如“频段 A 和 C 应该相对响亮,而频段 B 和 D 应该相对安静”之类的启发式方法,但它会如果有更系统的方法就好了。
有任何想法吗?
在我得到更好的结果之前,这里是图表的屏幕截图:

这是来自 Audacity 的一些类似数据的频谱:
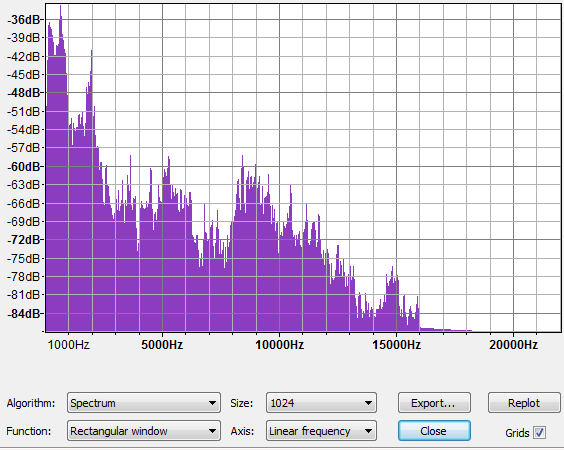
这是一个不同的声源,我只估计了样本的持续时间(在其他图像中以 8000 个样本/秒的速度为 1024 个样本)。该声音文件的采样率为 44.1K,因此它的高频数据比“现实生活”中可用的多得多。前三个峰值大约在 215Hz、600Hz 和 2000Hz。
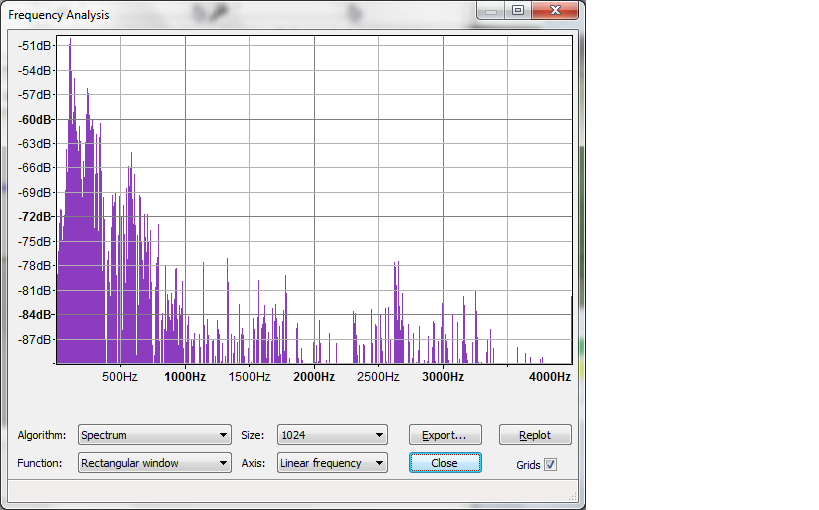
下一个来自不同的声音文件(和个人),其中声音级别要差得多。我们尤其在这些方面遇到了麻烦。峰值约为 124、248 和 581。
更新
我添加了代码来构建“过滤器”,方法是在峰值打鼾期间拍摄频谱快照(由现有的启发式方法确定),将几个连续的快照相加,“平滑”一点,并“标准化”到平均单位增益。在相对安静的时期拍摄的快照也是如此。然后,我将信号乘以两个滤波器,并(在频率范围内)两个乘积的差值相加以产生“增量”。这似乎产生了一个相当敏感的打鼾指标。
(这个描述有意义吗?)
就你能理解以上描述的程度而言,它有意义吗?一个简单的乘法是应用这种过滤器的最合理的方法吗?