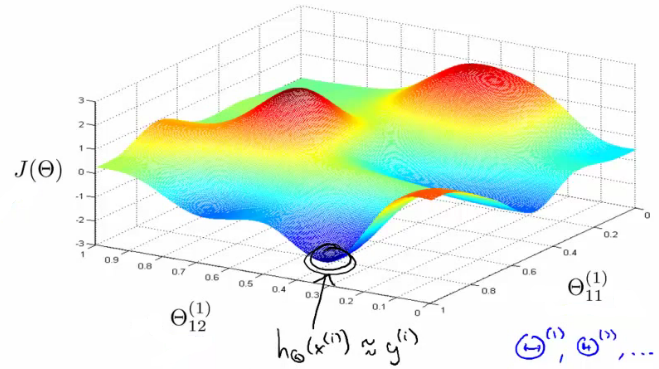
神经网络的代价函数是, 并且声称它是非凸的。我不太明白为什么会这样,因为我看到它与逻辑回归的成本函数非常相似,对吧?
如果是非凸的,那么二阶导数, 对?
更新
感谢下面的答案以及@gung 的评论,我明白了你的意思,如果根本没有隐藏层,它就是凸的,就像逻辑回归一样。但是如果有隐藏层,通过置换隐藏层中的节点以及后续连接中的权重,我们可以得到多个权重解,从而导致相同的损失。
现在更多的问题,
1)有多个局部最小值,其中一些应该具有相同的值,因为它们对应于一些节点和权重排列,对吧?
2)如果节点和权重根本不会被置换,那么它是凸的,对吧?最低标准将是全球最低标准。如果是这样,1) 的答案是,所有这些局部最小值都将具有相同的值,对吗?
{kind=link}