问题 2:解释这一观察结果的最佳方式是什么?例如,这种形状是否表明少数主要/主要语言最终会蚕食众多次要语言?
有多少个分区?看起来在大多数地区(大约 2 或 3000 人?)一种语言占主导地位,80% 或更多的人以这种语言为母语(高支配地位似乎比几乎没有支配地位更有可能)
结果,一个地区的其他语言只剩下 20%,这就形成了这个镜像。一种语言要么被许多人(得分 >80%)说,要么(因此)在另一边只有少数人(得分 <20%)说。
(可能会有一些说双语的人,但我认为在大多数情况下,在一个分区中,母语人士的比例应该达到或多或少 100%。)
简而言之:
您在 50% 左右的中间看不到很多语言,因为一个地区通常存在一种主导语言,这会导致高端的颠簸(代表以主流语言为母语的百分比),但也会导致低端的颠簸end(代表以非主要语言为母语的人的百分比)。
向该图表添加信息的一个好方法是制作一个堆叠图表,您可以在其中细分条形图,并为第一多语言、第二多语言和其他语言赋予不同的颜色。通过这种方式,您可以看到镜像是如何从右侧的主要(最常用的)语言创建的。剩下的在左边。
问题 1:为什么我们的分布大致类似于反正弦分布。请注意,我并不是说它在理论上一定是一个完美的反正弦值,而是在工程应用意义上,它足以假设最近的匹配分布以完成工作。我知道随机布朗运动会导致反正弦分布,但我不确定这是否是根本原因。
我不相信它像一维布朗运动那么简单。但也许制作一些地图并了解语言的分布情况可能会很有见地。
我想象的是,曲线的大部分由市长语言主导,这些语言集中在他们是第一语言的地区:
来自https://commons.m.wikimedia.org/wiki/File:Language_region_maps_of_India.svg#mw-jump-to-license
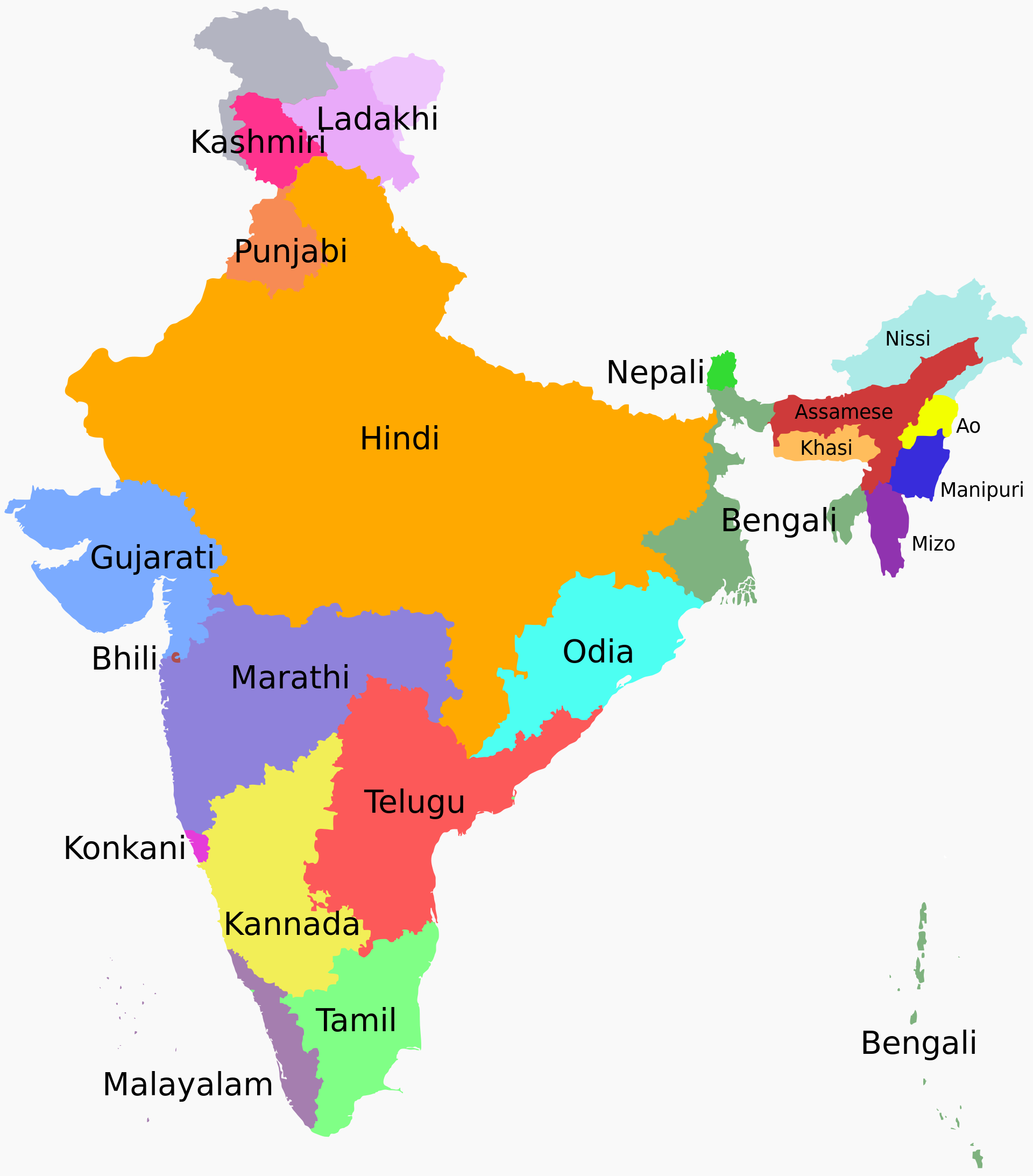
最重要的是,您可以想象这些语言在边界处的一些混合,这会导致分布偏离完美的 0/100% 分割。
您可能会将这种传播视为某种布朗运动过程(但可能带有一些吸引力)。并且语言远离其起源的可能性降低了,这样你就会得到一些可能与反正弦分布类似的分布,但它可能会更复杂,也许你可以更普遍地将它建模(近似)为 beta分布,但可能是更复杂的东西的混合物,恰好看起来像反正弦。

{kind=link}