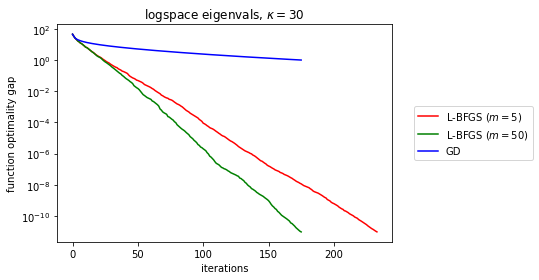
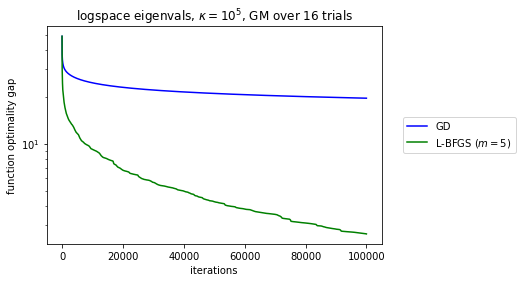
在实践中,L-BFGS 经常与其他不精确的 QN 方法相媲美,它在 Hestenes-Stiefel CG 和 BFGS 之间提供了一种中间立场,因为内存从零变为无穷大(数值优化第 7 章)。许多经验结果表明 L-BFGS 优于 GD,至少在某些大型设置类别中,例如非常强的凸函数和平滑函数。
Liu 和 Nocedal 1989证明了 L-BFGS 下降方向角与梯度在-第一次迭代,, 满足下限最终,在中等平滑度下确保类似 GD 的收敛特性:由于下降与 GD 足够一致,在满足 Wolfe 条件的线搜索下,我们得到全局最终收敛,对于平滑和强凸函数,我们实现线性收敛。
然而结果,局部和全局收敛特性来自关于满足 Wolfe 条件的任何下降方法的一般定理。L-BFGS 没有什么特别之处。事实上,用于的不等式结果似乎随着内存的增加而变弱。
具有较差常数的线性局部速率是违反直觉的,感觉就像理论和实践之间的差距。
是否有任何已知的理论结果,其中 L-BFGS 在足够规则的设置中提高了 GD 的线性速率(甚至它的平滑常数),理想情况下,以一种随着内存使用单调提高的方式?