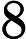有一个网络服务,我可以在其中请求有关随机项目的信息。对于每个请求,每个项目都有相同的机会被退回。
我可以继续请求项目并记录重复和唯一的数量。我如何使用这些数据来估计项目的总数?
有一个网络服务,我可以在其中请求有关随机项目的信息。对于每个请求,每个项目都有相同的机会被退回。
我可以继续请求项目并记录重复和唯一的数量。我如何使用这些数据来估计项目的总数?
这本质上是优惠券收集者问题的变体。
如果总共有n 个项目,并且您已使用替换样本大小s ,则识别出u个唯一项目的概率为 Pr(U=u|n,s) = \frac{S_2(s,u) n! }{(怒)!n^s } 其中S_2(s,u)给出第二类斯特林数
现在您只需要的先验分布,应用贝叶斯定理,并获得的后验分布。
我已经给出了基于第二类斯特林数和贝叶斯方法的建议。
对于那些发现斯特林数太大或贝叶斯方法太难的人,更粗略的方法可能是使用
并使用数值方法进行反算。
例如,以 GaBorgulya 的 和观察到的为例,这可能会给我们估计总体的。
如果那是总体,那么它会给我们一个大约 25 的方差,并且 265 两侧的任意两个标准差将是大约 255 和 275(正如我所说,这是一个粗略的方法)。255 会为我们提供大约 895 的估计值,而 275 会给出大约 1692 的估计值。示例的 1000 可以轻松地在此区间内。
您可以使用capture-recapture 方法,该方法也作为Rcapture R 包实现。
N = 1000; population = 1:N # create a population of the integers from 1 to 1000
n = 300 # number of requests
set.seed(20110406)
observation = as.numeric(factor(sample(population, size=n,
replace=TRUE))) # a random sample from the population, renumbered
table(observation) # a table useful to see, not discussed
k = length(unique(observation)) # number of unique items seen
(t = table(table(observation)))
模拟的结果是
1 2 3
234 27 4
因此,在 300 个请求中,有 4 个项目被查看了 3 次,27 个项目被查看了两次,234 个项目只被查看了一次。
现在从这个样本中估计 N:
require(Rcapture)
X = data.frame(t)
X[,1]=as.numeric(X[,1])
desc=descriptive(X, dfreq=TRUE, dtype="nbcap", t=300)
desc # useful to see, not discussed
plot(desc) # useful to see, not discussed
cp=closedp.0(X, dfreq=TRUE, dtype="nbcap", t=300, trace=TRUE)
cp
结果:
Number of captured units: 265
Abundance estimations and model fits:
abundance stderr deviance df AIC
M0** 265.0 0.0 2.297787e+39 298 2.297787e+39
Mh Chao 1262.7 232.5 7.840000e-01 9 5.984840e+02
Mh Poisson2** 265.0 0.0 2.977883e+38 297 2.977883e+38
Mh Darroch** 553.9 37.1 7.299900e+01 297 9.469900e+01
Mh Gamma3.5** 5644623606.6 375581044.0 5.821861e+05 297 5.822078e+05
** : The M0 model did not converge
** : The Mh Poisson2 model did not converge
** : The Mh Darroch model did not converge
** : The Mh Gamma3.5 model did not converge
Note: 9 eta parameters has been set to zero in the Mh Chao model
因此只有 Mh Chao 模型收敛,它估计 =1262.7。
> round(quantile(Nhat, c(0, 0.025, 0.25, 0.50, 0.75, 0.975, 1)), 1)
0% 2.5% 25% 50% 75% 97.5% 100%
657.2 794.6 941.1 1034.0 1144.8 1445.2 2162.0
> mean(Nhat)
[1] 1055.855
> sd(Nhat)
[1] 166.8352