最近,我对声誉对赞成票的影响进行了一些分析(请参阅博客文章),随后我对可能更具启发性(或更合适)的分析和图形提出了一些问题。
所以有几个问题(并且随时特别回答任何人并忽略其他问题):
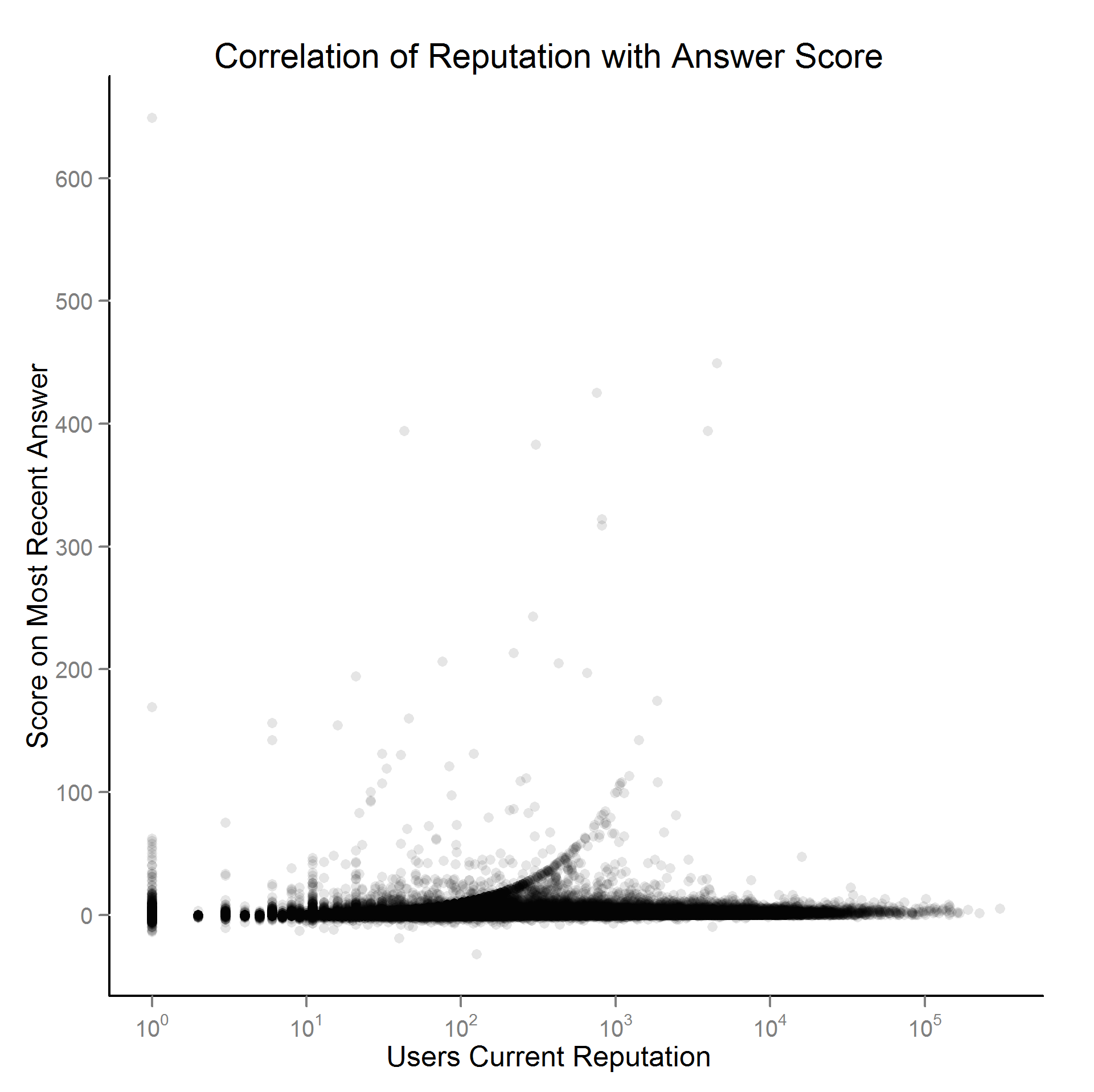
在目前的化身中,我并不是说以职位编号为中心。我认为这会在散点图中给出负相关的错误外观,因为在帖子计数的低端有更多帖子(你会看到这在 Jon Skeet 面板中不会发生,仅在凡人用户中)控制板)。不将帖子编号居中是否不合适(因为我的意思是使每个用户的平均得分居中)?
从图中可以明显看出,分数是高度右偏的(平均居中并没有改变这一点)。在拟合回归线时,我拟合了线性模型和使用 Huber-White Sandwhich 误差的模型(通过
rlmMASS R 包中),它对斜率估计没有任何影响。我应该考虑对数据进行转换而不是稳健回归吗?请注意,任何转换都必须考虑到 0 和负分的可能性。或者我应该使用其他类型的模型来计算数据而不是 OLS?我相信最后两个图形通常可以改进(并且也与改进的建模策略有关)。在我(厌倦)看来,我怀疑声誉效应是否真实,它们会在海报历史的早期实现(我想如果是真的,这些可能会被重新考虑“你给出了一些很好的答案,所以现在我会支持你所有的帖子”而不是“总分的声誉”效果)。在考虑过度绘图的同时,如何创建图形来证明这是否属实?我想也许证明这一点的一个好方法是拟合表格的模型;
其中是(与当前散点图中),是 _邮政编号等)。和分别是大截距和误差项。然后我将检查估计的斜率以确定声誉效应是否在海报历史的早期出现(或以图形方式显示它们)。这是一个合理(和适当)的方法吗?score - (mean score per user)post number11 through 25126 through 50
将某种类型的非参数平滑线拟合到像这样的散点图(例如黄土或样条线)似乎很流行,但我对样条线的实验并没有揭示任何启发性(在海报历史早期的任何积极影响的证据都是轻微和喜怒无常的到我包括的样条数)。由于我假设效果很早就发生了,我的建模方法是否比样条曲线更合理?
另请注意,尽管我已经挖掘了所有这些数据,但仍有许多其他社区需要检查(有些像超级用户和 serverfault 也有类似的大样本可供提取),因此将来提出建议是很合理的我使用保留样本来检查任何关系的分析。
{kind=link}