我们可以首先更一般地思考因果图到底是什么。然后让我们讨论如何实际使用它们作为信息先验,并与观察数据一起,自信地预测因果关系。
因果图是分布内变量(即节点)之间函数关系的有向无环图(DAG)表示。并且图的结构用于编码变量之间的条件依赖或独立。该图本质上以易于理解的视觉格式断言了我们对世界的假设。提供联合分布 p(a,b,c),相同的分布可以写成:
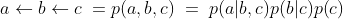
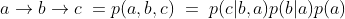
那么哪个因果图是联合分布的正确因果图呢?该示例表明因果图与我们的观察数据的映射是多对一的。多个正确的假设是合理的,并且通常不可能仅通过观察观察数据在它们之间做出明确的选择。
那么我们如何使用观测数据来推断正确的图表呢?对于上述因果图,我们通过调节变量来模拟干预的效果(即,我们强制它采用特定值)。该动作由 p(Y|do(X)) 中的 do-operator 封装,更正式地由 do-calculas 封装,do-calculas 是一种用于因果推理的工具,它允许我们从观测数据中消除需要估计的内容。前门和后门方法只是两扇门,我们可以通过它们消除攀登干预山的所有工作。
可以说,通过删除感兴趣节点的所有传入边,干预将原始联合分布修改为干预后分布。如果我们可以删除所有操作符,则因果查询变得可识别,因此我们可以使用观察数据来估计因果效应。否则,因果查询被认为是不可识别的,并且需要进行真实世界的干预实验来确定因果关系。
虽然研究人员可能永远不会完全相信他们构建的因果图的合理性和完整性,但他们确实有适当的机制来凭经验测试变量集之间的部分关系集合。如果观测数据中不存在相关性和独立性,这可能是图表不准确的信号。然后,研究人员可以迭代地测试和更新因果图,使其更符合观测数据中包含的信息(以及适用的领域知识)。