我从图书馆的文档中遵循这个例子scikit-fuzzy,但无法弄清楚模糊规则背后的数学。
这是该示例的简短版本。
食品质量为 6.5(中等)
服务为 9.8(很好)
食品质量和服务范围为 [0, 10]
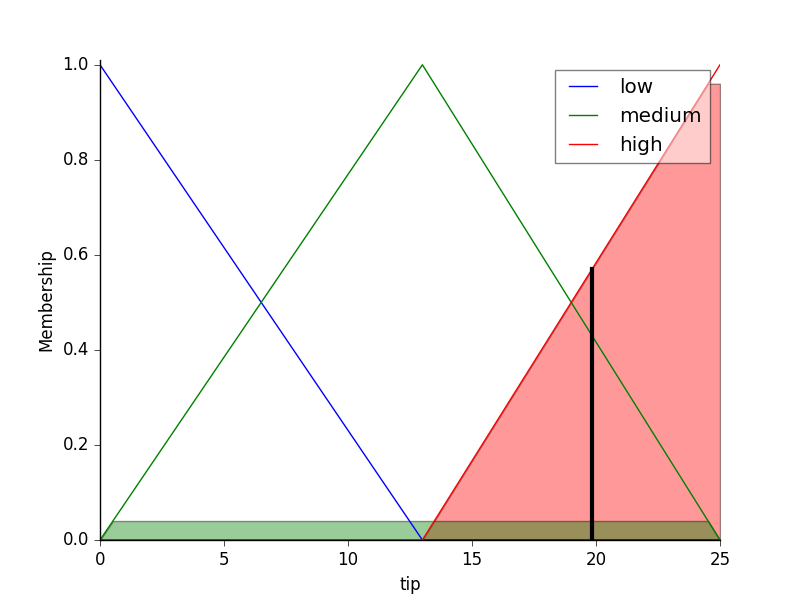
小费金额范围为 [0, 25]规则:
- 如果食物不好或服务很差,那么小费会很低
- 如果服务可以接受,那么小费将是中等的
- 如果食物很棒或服务很棒,那么小费会很高。
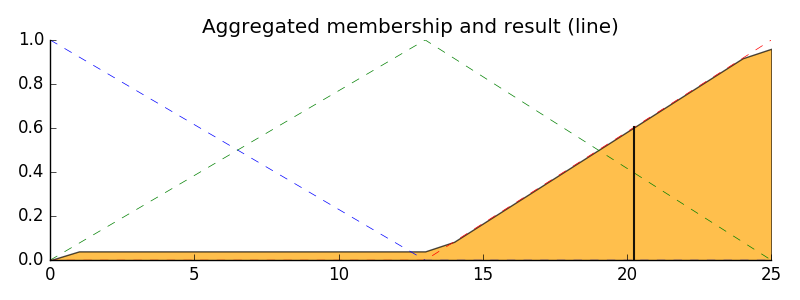
计算的小费金额为20.2。我的问题是,这是如何计算的?
我以这种方式手动解决了这个问题:
由于食物“很棒”,我应用了规则 3.
质量为 % = 6.5/11(11 是评分范围)
服务为 % = 9.8/11
max(6.5/11 , 9.8/11) * 26 = 23.16 (26为小费范围)