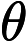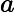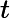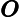我正在尝试学习机器学习,但我不确定这些术语的含义。我知道可能性是要学习的参数的函数,我们希望最大化它,但我也知道我们使用损失函数拟合模型......
有人可以给出不同模式下的示例(例如离散朴素贝叶斯或逻辑回归中的 MLE 是什么),以及它们与损失函数的关系如何?
我正在尝试学习机器学习,但我不确定这些术语的含义。我知道可能性是要学习的参数的函数,我们希望最大化它,但我也知道我们使用损失函数拟合模型......
有人可以给出不同模式下的示例(例如离散朴素贝叶斯或逻辑回归中的 MLE 是什么),以及它们与损失函数的关系如何?
损失函数是作为模型参数函数的模型失配的度量。损失函数比单纯的 MLE 更通用。
MLE 是一种特定类型的概率模型估计,其中损失函数是(对数)似然。套用 Matthew Drury 的评论,MLE 是证明概率模型损失函数的一种方法。
在神经网络等机器学习应用中,损失函数用于评估模型的拟合优度。例如,考虑一个简单的神经网络,它有一个神经元和一个线性(恒等式)激活,它有一个输入和一个输出:
我们在样本数据集上训练这个 NN:,观察。训练正在尝试不同的参数值,并使用损失函数检查拟合的好坏。假设我们要使用二次成本:
那么我们有以下损失:
学习意味着最小化这种损失:
你可以选择任何你想要的损失函数,或者适合你的问题。但是,有时损失函数选择遵循 MLE 方法来解决您的问题。例如,如果您处理高斯线性回归,则二次成本和上述损失函数是自然选择。就是这样。
假设您以某种方式知道真正的模型是和 - 具有恒定方差的随机高斯误差。如果情况确实如此,那么参数的 MLE与使用上述具有二次成本(损失)的 NN 的最优解相同。
请注意,在 NN 中,您不必总是选择与某种 MLE 方法匹配的成本(损失)函数。此外,虽然我使用神经网络描述了这种方法,但它适用于机器学习及其他领域的其他统计学习技术。
在机器学习中,很多人不会过多地谈论假设(例如残差为高斯)。许多人认为这个问题是一个确定性问题,其中给出了(大量)数据,我们希望将损失最小化。
在经典统计文献中,通常数据不会太多,人们谈论模型的概率解释,其中有很多概率假设(例如残差为高斯)。使用概率假设,可以计算似然性,并且损失函数可以是负似然性,而不是(或作为)最小化错误分类率的代表。
考虑生成模型与判别模型的观点也很有趣。最大化似然通常来自生成模型,最小化损失通常来自判别模型。